在當(dāng)今信息爆炸的時(shí)代,高效地獲取和處理網(wǎng)絡(luò)數(shù)據(jù)已成為企業(yè)和機(jī)構(gòu)的重要需求。網(wǎng)絡(luò)爬蟲(Web Crawler)作為一項(xiàng)核心技術(shù),在北京計(jì)算機(jī)系統(tǒng)服務(wù)領(lǐng)域扮演著越來越關(guān)鍵的角色。本文將從網(wǎng)絡(luò)爬蟲的基本原理入手,探討其在計(jì)算機(jī)系統(tǒng)服務(wù)中的應(yīng)用與挑戰(zhàn)。
一、網(wǎng)絡(luò)爬蟲的定義與工作原理
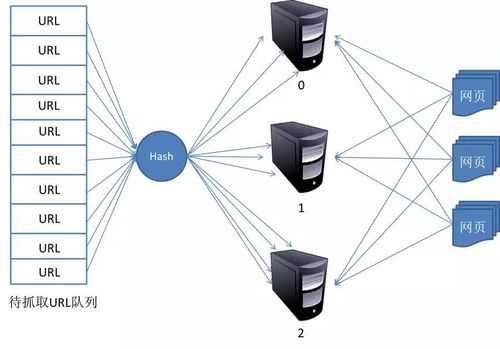
網(wǎng)絡(luò)爬蟲,又稱網(wǎng)絡(luò)蜘蛛或網(wǎng)絡(luò)機(jī)器人,是一種按照預(yù)設(shè)規(guī)則自動(dòng)抓取互聯(lián)網(wǎng)信息的程序或腳本。其核心工作原理可概括為以下幾步:
- 種子URL設(shè)定:爬蟲從初始的URL列表(種子URL)開始工作,這些URL通常由用戶指定。
- 頁面抓取:爬蟲通過HTTP/HTTPS協(xié)議訪問目標(biāo)網(wǎng)頁,下載頁面內(nèi)容(通常是HTML代碼)。
- 數(shù)據(jù)解析:解析下載的頁面,提取有用信息(如文本、圖片鏈接等),并識別頁面中的其他鏈接。
- 鏈接追蹤:將新發(fā)現(xiàn)的鏈接加入待抓取隊(duì)列,循環(huán)執(zhí)行抓取和解析過程,直到滿足停止條件(如達(dá)到深度限制或抓取數(shù)量)。
- 數(shù)據(jù)存儲:將提取的結(jié)構(gòu)化數(shù)據(jù)保存到數(shù)據(jù)庫或文件中,供后續(xù)分析使用。
二、網(wǎng)絡(luò)爬蟲的關(guān)鍵技術(shù)要點(diǎn)
- 請求與響應(yīng)處理:爬蟲需要模擬瀏覽器行為發(fā)送請求,并處理服務(wù)器的響應(yīng)(包括狀態(tài)碼、重定向等)。
- 解析技術(shù):常用HTML解析庫(如BeautifulSoup、lxml)或正則表達(dá)式來提取數(shù)據(jù),現(xiàn)代爬蟲也常結(jié)合JavaScript渲染工具(如Selenium)處理動(dòng)態(tài)頁面。
- 去重策略:通過哈希算法或布隆過濾器避免重復(fù)抓取相同URL,提高效率。
- 遵守robots協(xié)議:尊重網(wǎng)站的robots.txt文件,避免抓取被禁止的頁面,體現(xiàn)合法合規(guī)性。
- 反爬蟲應(yīng)對:針對IP封鎖、驗(yàn)證碼等反爬機(jī)制,需采用代理IP池、請求頭偽裝或延遲請求等技術(shù)。
三、網(wǎng)絡(luò)爬蟲在北京計(jì)算機(jī)系統(tǒng)服務(wù)中的應(yīng)用
北京作為科技創(chuàng)新中心,其計(jì)算機(jī)系統(tǒng)服務(wù)行業(yè)廣泛利用網(wǎng)絡(luò)爬蟲技術(shù)支撐業(yè)務(wù)發(fā)展:
- 市場調(diào)研與競爭分析:企業(yè)通過爬蟲收集行業(yè)數(shù)據(jù)、產(chǎn)品價(jià)格和用戶評論,輔助決策制定。
- 輿情監(jiān)控:政府或機(jī)構(gòu)實(shí)時(shí)抓取新聞、社交媒體信息,及時(shí)感知公眾意見和突發(fā)事件。
- 垂直信息聚合:在招聘、房產(chǎn)、電商等領(lǐng)域,服務(wù)商整合多平臺數(shù)據(jù)提供一站式查詢服務(wù)。
- 學(xué)術(shù)與科研:高校及研究機(jī)構(gòu)抓取公開論文、專利數(shù)據(jù),支持學(xué)術(shù)分析與技術(shù)創(chuàng)新。
- 安全監(jiān)測:網(wǎng)絡(luò)安全公司利用爬蟲掃描漏洞、追蹤威脅情報(bào),增強(qiáng)系統(tǒng)防護(hù)能力。
四、挑戰(zhàn)與合規(guī)性考量
在北京開展計(jì)算機(jī)系統(tǒng)服務(wù)時(shí),網(wǎng)絡(luò)爬蟲的應(yīng)用需注意以下問題:
- 法律與倫理邊界:嚴(yán)格遵守《網(wǎng)絡(luò)安全法》等法規(guī),避免侵犯隱私、知識產(chǎn)權(quán)或構(gòu)成不正當(dāng)競爭。
- 數(shù)據(jù)安全:確保抓取的數(shù)據(jù)存儲與傳輸安全,防止泄露敏感信息。
- 資源消耗控制:合理設(shè)置抓取頻率,避免對目標(biāo)網(wǎng)站服務(wù)器造成過大壓力。
- 技術(shù)更新適應(yīng):隨著網(wǎng)站反爬技術(shù)升級,爬蟲系統(tǒng)需持續(xù)優(yōu)化以保持有效性。
五、未來發(fā)展趨勢
在北京計(jì)算機(jī)系統(tǒng)服務(wù)的推動(dòng)下,網(wǎng)絡(luò)爬蟲技術(shù)正朝著智能化、分布式和合規(guī)化方向發(fā)展:
- AI融合:結(jié)合自然語言處理和機(jī)器學(xué)習(xí),提升數(shù)據(jù)提取的準(zhǔn)確性和語義理解能力。
- 云化與分布式架構(gòu):利用云計(jì)算資源實(shí)現(xiàn)大規(guī)模并發(fā)抓取,提高效率和可擴(kuò)展性。
- API優(yōu)先策略:越來越多網(wǎng)站提供開放API,鼓勵(lì)合法數(shù)據(jù)交換,減少對爬蟲的依賴。
- 合規(guī)自動(dòng)化工具:開發(fā)集成法律規(guī)則檢測的爬蟲系統(tǒng),自動(dòng)規(guī)避合規(guī)風(fēng)險(xiǎn)。
網(wǎng)絡(luò)爬蟲作為連接海量網(wǎng)絡(luò)數(shù)據(jù)與計(jì)算機(jī)系統(tǒng)服務(wù)的橋梁,其基本原理的深入理解和正確應(yīng)用,對于北京乃至全國的數(shù)字化轉(zhuǎn)型具有重要意義。服務(wù)提供商應(yīng)在技術(shù)創(chuàng)新與合規(guī)經(jīng)營之間找到平衡,以促進(jìn)健康、可持續(xù)的數(shù)據(jù)生態(tài)發(fā)展。